My latest column for Quanta Magazine ties recent news about “digitally delicate” primes to some simple but fascinating results about prime numbers.
You may have noticed that mathematicians are obsessed with prime numbers. What draws them in? Maybe it’s the fact that prime numbers embody some of math’s most fundamental structures and mysteries. The primes map out the universe of multiplication by allowing us to classify and categorize every number with a unique factorization. But even though humans have been playing with primes since the dawn of multiplication, we still aren’t exactly sure where primes will pop up, how spread out they are, or how close they must be. As far as we know, prime numbers follow no simple pattern.
There’s a tension among the infinitude of prime numbers — that there will always be primes close together and primes far apart — that can also be seen among digitally delicate primes, primes that become composite if any digit is changed. It may come as a surprise that any digitally delicate primes exist at all, but that’s just the beginning of their story. Find out more at by reading the full article here, and be sure to check out the exercises!
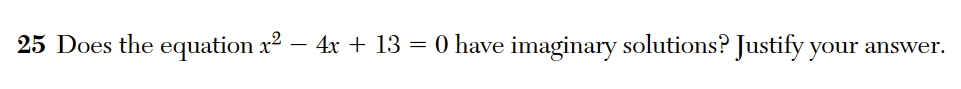
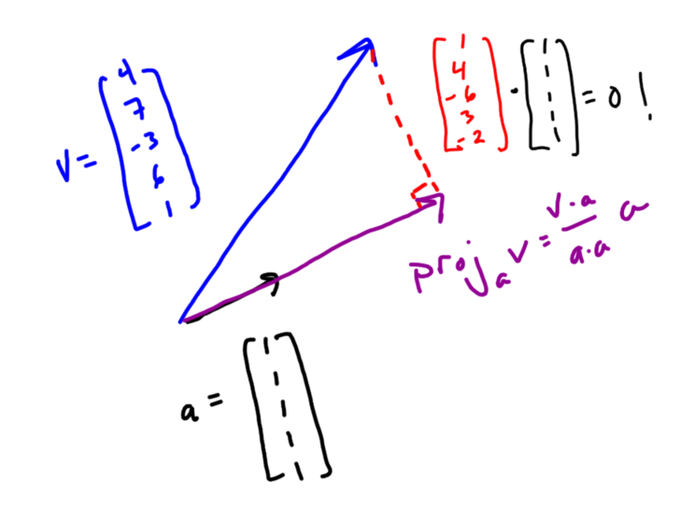
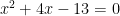 has “imaginary solutions”, that is, if the solutions to this equation, 2 +3i and 2 – 3i, are imaginary numbers. These solutions are complex but not imaginary, because imaginary numbers are multiples of i, the imaginary unit. Therefore the answer should be no, this equation does not have imaginary solutions.
has “imaginary solutions”, that is, if the solutions to this equation, 2 +3i and 2 – 3i, are imaginary numbers. These solutions are complex but not imaginary, because imaginary numbers are multiples of i, the imaginary unit. Therefore the answer should be no, this equation does not have imaginary solutions.