My latest column for Quanta Magazine is about one of the most dreaded mathematical objects in high school math: the quadratic formula!
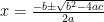
As complicated as the quadratic formula is, the cubic formula is much worse, but a simple geometric idea connects the two.
As intimidating as this looks, hiding inside is a simple secret that makes solving every quadratic equation easy: symmetry. Let’s look at how symmetry makes the quadratic formula work and how a lack of symmetry makes solving cubic equations much, much harder. So much harder, in fact, that a few mathematicians in the 1500s spent their lives embroiled in bitter public feuds competing to do for cubics what was so easily done for quadratics.
You can read the full article here.